Kubernetes architecture
Let’s start by looking at Kubernetes from a very high level, and then gradually zoom in. When starting at this high level, a simple way to think about Kubernetes is as an operating system for your data center.
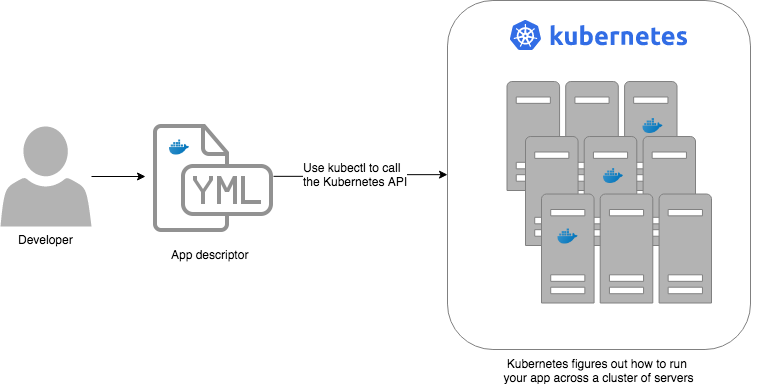 Kubernetes is like an operating system for your data center, abstracting away the underlying hardware behind its API
Kubernetes is like an operating system for your data center, abstracting away the underlying hardware behind its API
Operating system for a single computer
On a single computer, the operating system (e.g., Windows, Linux, macOS) abstracts away all the low-level hardware details so that as a developer, you can build apps against a high-level, consistent, safe API (the Kernel API), without having to worry too much about the differences between many types of hardware (i.e., the many types of CPU, RAM, hard drive, etc) or about managing any of the applications running on that hardware (i.e., the OS handles device drivers, time sharing, memory management, process isolation, etc).
Operating system for a data center
In a data center, an orchestration tool like Kubernetes also abstracts away all the hardware details, but it does it for multiple computers (multiple servers), so that as a developer, you can deploy your applications using a high-level, consistent, safe API (the Kubernetes API), without having to worry too much about the differences between the servers or about managing any of the applications running on those servers (i.e., the orchestration tool handles deploying applications, restarting them if they fail, allowing them to communicate over the network, etc.).
To use the Kernel API, your application makes system calls. To use the Kubernetes API, you make HTTPS calls, typically
by using the official command-line utility for Kubernetes,
kubectl. When working with the Kubernetes API, you express
what you want to deploy—i.e., which Docker containers, how many of them, what CPU, memory, and ports they need,
etc—in a YAML file, use kubectl to send that YAML file to Kubernetes via an API call, and Kubernetes will
figure out how to make that happen, including picking the best servers to handle the requirements in your YAML file,
deploying the containers on those servers, monitoring and restarting the containers if they crash, scaling the number
of containers up and down with load, and so on.
If you zoom in a bit further on the Kubernetes architecture, it looks something like this:
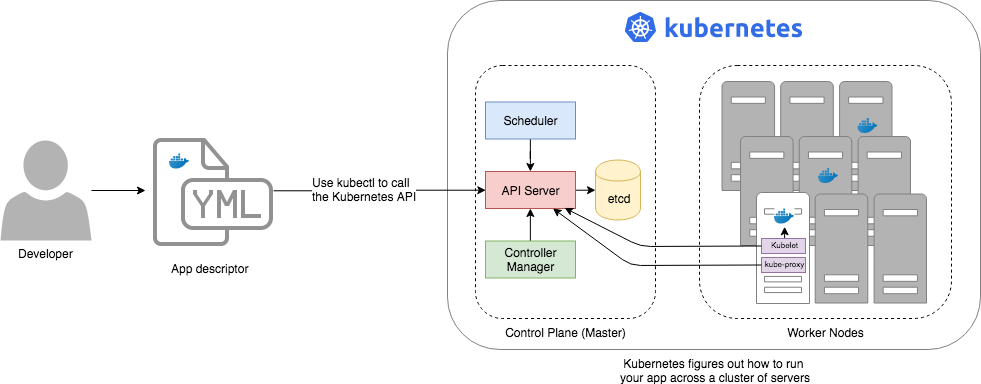 Kubernetes architecture
Kubernetes architecture
Kubernetes consists of two main pieces: the control plane and worker nodes. Each of these will be discussed next.
Control plane
The control plane is responsible for managing the entire cluster. It consists of one or more master nodes (typically 3 master nodes for high availability), where each master node runs several components:
Kubernetes API Server
The Kubernetes API Server is the
endpoint you’re talking to when you use the Kubernetes API (e.g., via kubectl).
Scheduler
The scheduler is responsible for figuring out which of the worker nodes to use to run your container(s). It tries to pick the "best" worker node based on a number of factors, such as high availability (try to run copies of the same container on different nodes so a failure in one node doesn’t take them all down), resource utilization (try to run the container on the least utilized node), container requirements (try to find nodes that meet the container’s requirements in terms of CPU, memory, port numbers, etc), and so on.
Controller Manager
The controller manager runs all the controllers, each of which is a control loop that continuously watches the state of the cluster and makes changes to move the cluster towards the desired state (you define the desired state via API calls). For example, the node controller watches worker nodes and tries to ensure the requested number of Nodes is always running and the replication controller watches containers and tries to ensure the requested number of containers is always running.
etcd
etcd is a distributed key-value store that the master nodes use as a persistent way to store the cluster configuration.
Worker nodes
The worker nodes (or just nodes, for short) are the servers that run your containers. Each worker node runs several components:
Kubelet
The kubelet is the primary agent that you run on each worker node. It is responsible for talking to the Kubernetes API Server, figuring out the containers that are supposed to be on its worker node, and deploying those containers, monitoring them, and restarting any containers that are unhealthy.
kube-proxy
The Kubernetes Service Proxy (kube-proxy) also runs on each worker node. It is responsible for talking to the Kubernetes API Server, figuring out which containers live at which IPs, and proxying requests from containers on the same worker node to those IPs. This is used for Service Discovery within Kubernetes, a topic we’ll discuss later.